Mnist 手写数字识别入门
- https://www.cnblogs.com/jzssuanfa/p/19370191
- https://zhuanlan.zhihu.com/p/633468940
- Colab
- 动手学深度学习
- https://www.kaggle.com/code/thomastschinkel/ml-with-the-iris-dataset-a-comprehensive-guide
机器学习界的hello world,很久之前就对机器学习感兴趣了,一直很想搞明白是那些程序和模型是如何通过“训练”去像人类一样处理数据的,但是因为专业不符方向也不一致完全没看过,虽然说最近也不闲,但我还是决定了解一下这个东西,也算是找一个能让我沉下心去研究的东西
给毕设之类的打打基础,通过训练模型监控流量特征之类的……
(挖洞头太疼了,感觉很无聊,先把这个搞完吧,之后考研的闲暇或许想学一下如何实现LLM
前置
MNIST
MNIST 问题是由 Yann LeCun、Corinna Cortes 和 Christopher Burges 为评估机器学习模型在手写数字分类问题上的表现而开发的一个数据集。该数据集是从国家标准与技术研究院(NIST)提供的若干扫描文档数据集中构建的。这也是数据集名称的来源,即 Modified NIST 或 MNIST 数据集。
数字图像来自各种扫描文档,大小归一化并居中。这使它成为评估模型的极好数据集,开发者可以在最少的数据清理或准备工作下专注于机器学习。每张图像都是一个 28 x 28 像素的正方形(总共 784 像素)。数据集使用标准分割来评估和比较模型,其中 60,000 张图像用于训练模型,另外一组 10,000 张图像用于测试。
这是一个数字识别任务。因此有十个数字(0 到 9)或十个类别需要预测。结果以预测误差来报告,简单来说就是分类准确度的取反。出色的结果的预测误差小于 1%。使用大型卷积神经网络可以达到约 0.2% 的前沿预测误差
KERAS
Keras 是一个用 Python 编写的开源深度学习(Deep Learning)高级 API/框架,用于快速构建和训练神经网络模型,它是比较高层的神经网络API,可以简化模型构建
比如你用Keras写代码,实际上的运算在深度学习框架的后端执行库,比如TensorFlow或者PyTorch等(tf自带tf.keras)
numpy
一个数值计算库,NumPy 的核心数据结构是 ndarray(N 维数组),比 Python 内置的 list 更紧凑、更快、更适合做数学运算,器学习的数据(特征矩阵、标签、图像、时间序列等)通常以 矩阵/张量形式存储,NumPy 数组能高效处理这些数据
import numpy as np
X = np.array([[1, 2], [3, 4]])Coding
数据集
我们先从mnist下载手写数字的数据集
import tensorflow as tf
from tensorflow.keras.datasets import mnist
import matplotlib .pyplot as plt
# python绘图库
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 从mnist加载训练集和测试集其中X_train的形状是(60000, 28, 28) 即60000张28X28的灰度图
y_train对应数字标签0~9
我们可以创建一个脚本导出几张数据集看看
import tensorflow as tf
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
# python绘图库
import matplotlib
matplotlib.use('Agg') #这里我使用ssh服务器连接的,所以使用无gui
fig = plt.figure(figsize=(6,6))
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 从mnist加载训练集和测试集,会自动下载
plt.subplot(221)
# 创建一个2X2的图
plt.imshow(X_train[0], cmap=plt.get_cmap('gray'))
plt.subplot(222)
plt.imshow(X_train[1], cmap=plt.get_cmap('gray'))
plt.subplot(223)
plt.imshow(X_train[2], cmap=plt.get_cmap('gray'))
plt.subplot(224)
plt.imshow(X_train[3], cmap=plt.get_cmap('gray'))
fig.savefig("output.png")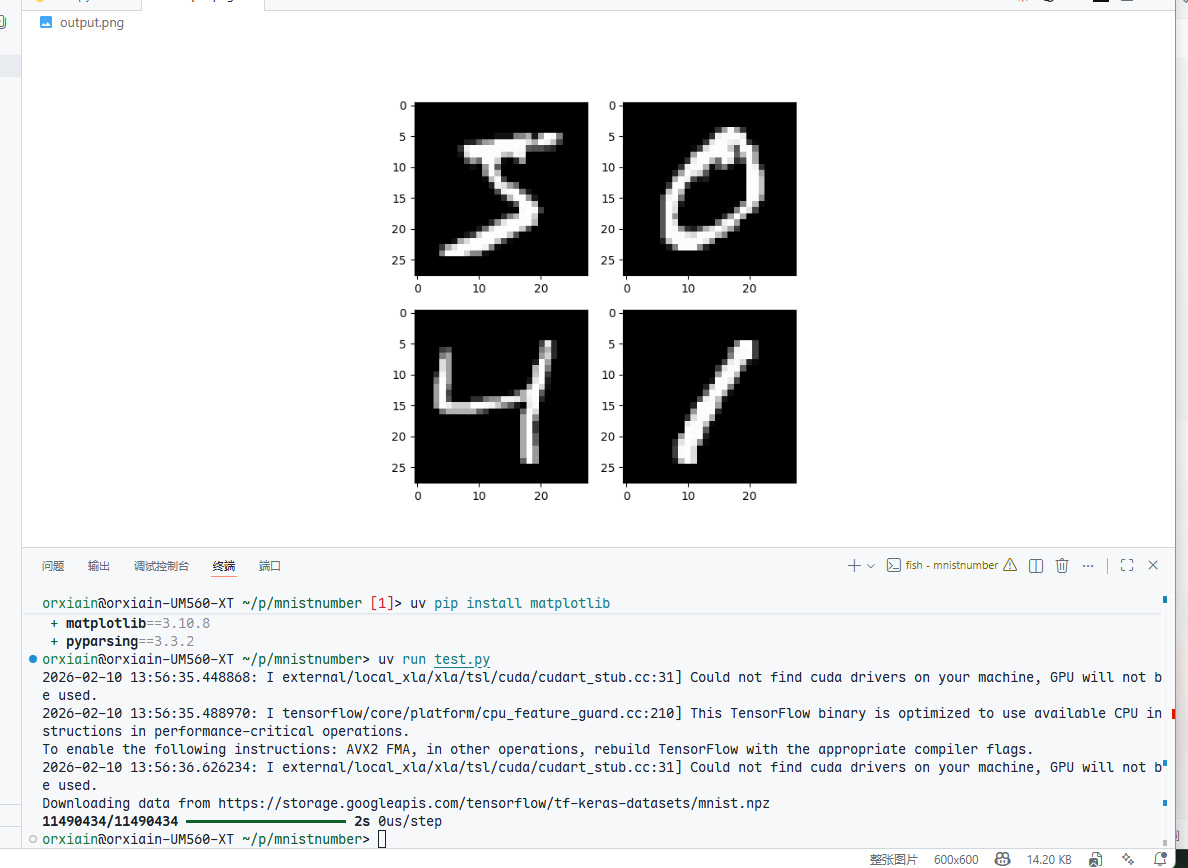
MLP
首先采用多层感知机MLP去构建模型 也就是单隐藏层的全连接神经网络 导入numpy,设置随机种子,加载数据集
import numpy as np
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras import utils
seed = 3
np.random.seed(seed) # 设置随机种子
(X_train, y_train), (X_test, y_test) = mnist.load_data()将每个像素都有灰度值,全部除以255进行归一化
X_train = X_train / 255
X_test = X_test / 255y_train[0]的内容是图片上的数字,在神经网络的输出层,输出的格式类似于[0,0,0,0,0,1,0,0,0,0],这就是one-shot编码的5
我们使用如下代码,将对应的数字标签转换为one-shot编码
y_train = utils.to_categorical(y_train)
y_test = utils.to_categorical(y_test)然后我们通过y_test.shape获取类别数量,y_test.shape此处的内容是(10000, 10),代表了共有10000个样本,10个类别维度,这里的num_classes用于定义输出层
num_classes = y_test.shape[1]构建baseline模型,结构如下
输入(784)
↓
隐藏层(784, ReLU)
↓
输出层(10, Softmax)model.add(Dense(num_pixels, input_dim=num_pixels, kernel_initializer='normal',
activation='relu'))首先定义输入层,第一个参数是神经元数量,同时就是输出的向量维度(因为是全连接层)。第二个参数input_dim,输入784维向量特征,也就是这里的input_dim(权重矩阵 W 的列数)
这里的意思就是输入784个数,输出784个神经元,矩阵大小是
神经网络便是不断地修改每个像素对应的权重,使结果与测试集更加接近
kernel_initializer是便是得到权重W初始值的方法,若W = 0,则所有神经元的输出内容都一样,网络无法学习,规定为normal则从正态分布中随机抽样,所以这里规定为normal,也就是随机数
每个神经元做完线性计算之后,需要再对结果进行activation(再套一层函数,也就是激活函数)
这里的relu的本质公式是ReLU(x)=max(0,x),若x>0则保留结果,≤0则变为0
就是这个特征明显的话就激活这个神经元,不明显则关闭,总的来说activation决定神经元的激活状态,为网络提供了学习复杂的非线性函数的能力
我们来看第二层输出层
model.add(Dense(num_classes, kernel_initializer='normal', activation='softmax'))这一层用来加权求和。一个神经元有784个权重,那么权重矩阵的大小是 定义10个神经元来输出0~9 这里激活函数指定softmax,其具体计算是 softmax 的输出常被解释为类别概率,输出的概率之和为1
最后我们通过compile规定训练规则
loss参数是采用的损失函数,来衡量离标准答案有多错
交叉熵损失函数(Cross-Entropy Loss) 是深度学习中分类任务最常用的损失函数。它主要衡量模型预测的概率分布与真实标签的概率分布之间的“距离”。
如果差的不多,则损失值较小,反之则较大。再得到一轮预测结果并计算得到损失之后,我们需要更改神经元的权重,尽量地去减少损失,那么如何去更改权重?总不能是随机取吧?这里就需要用到optimizer,optimizer是优化器,来告诉模型如何去改权重
要理解这个我们先搞清楚 梯度下降算法
梯度下降是一种通过不断沿“损失函数下降最快的方向”更新参数,从而让损失变小的优化算法
假设我们有个函数是 最低点在 ,若你在的位置,导数为10,代表了此处的坡度很大,那么为了减小梯度,我们就要向反方向走,规定 假设这里的学习率是0.1,经过计算我们得到下一个x的值是4,离0近了一步,那么不断地重复将使得结果接近于0, 这就是梯度下降
那么当损失函数为 (W为所有权重),梯度下降所做的就是: 去计算每个权重的偏导数并按照反方向去更新 这里我们采用的Adam是一种改良后的梯度下降算法,这里不展开了
最终得到一下代码
def baseline_model():
# create model
model = Sequential()
model.add(Dense(num_pixels, input_dim=num_pixels, kernel_initializer='normal',
activation='relu'))
model.add(Dense(num_classes, kernel_initializer='normal', activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model接下来进行训练,用到的函数是model.fit
model = baseline_model() # 获取一个模型
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200,
verbose=2)
scores = model.evaluate(X_test, y_test, verbose=0)
print("Baseline Error: %.2f%%" % (100-scores[1]*100))这里的epochs表示把整个数据集看10遍,每次看200张,verbose值为2意思是每轮打印一行结果,1约定为进度条 最后我们用测试集计算我们模型的成绩
scores = model.evaluate(X_test, y_test, verbose=0)最终的代码如下
import numpy as np
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras import utils
seed = 3
np.random.seed(seed)
(X_train, y_train), (X_test, y_test) = mnist.load_data()
num_pixels = X_train.shape[1] * X_train.shape[2]
X_train = X_train.reshape(X_train.shape[0], num_pixels).astype('float32')
X_test = X_test.reshape(X_test.shape[0], num_pixels).astype('float32')
X_train = X_train / 255
X_test = X_test / 255
y_train = utils.to_categorical(y_train)
y_test = utils.to_categorical(y_test)
num_classes = y_test.shape[1]
print(y_test.shape)
def baseline_model():
# create model
model = Sequential()
model.add(Dense(num_pixels, input_dim=num_pixels, kernel_initializer='normal',
activation='relu'))
model.add(Dense(num_classes, kernel_initializer='normal', activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
model = baseline_model()
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200,
verbose=2)
scores = model.evaluate(X_test, y_test, verbose=0)
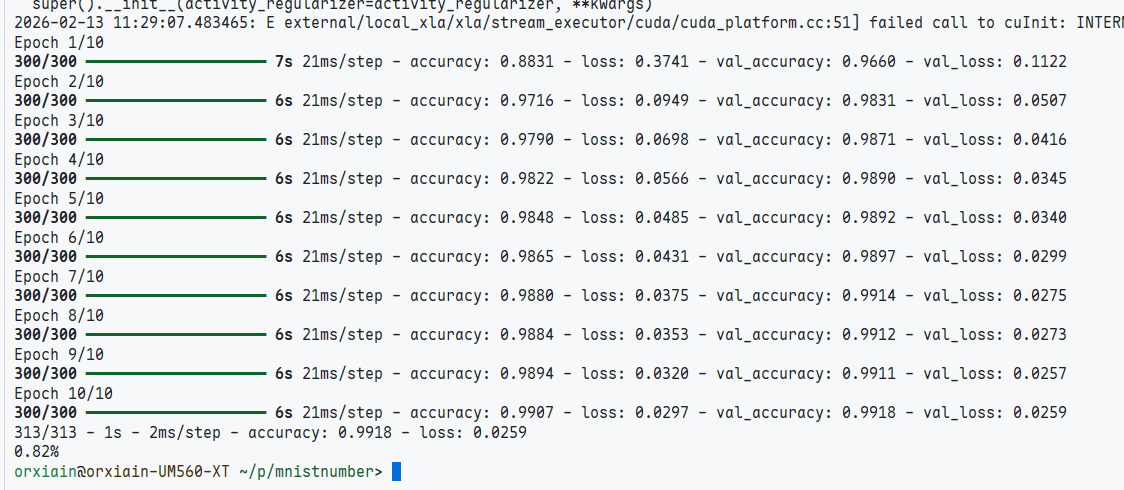
print("Baseline Error: %.2f%%" % (100-scores[1]*100))运行结果如下
 可以看到在前300次的权重更新中,准确度就来到了0.92,验证集的loss val_loss下降到了0.06,训练集下降到了0.0078
在最终最后两轮的训练中,验证集的准确率反而下降了,这代表了对于新数据的泛化能力不再提升,开始出现一定程度的过拟合
可以看到在前300次的权重更新中,准确度就来到了0.92,验证集的loss val_loss下降到了0.06,训练集下降到了0.0078
在最终最后两轮的训练中,验证集的准确率反而下降了,这代表了对于新数据的泛化能力不再提升,开始出现一定程度的过拟合
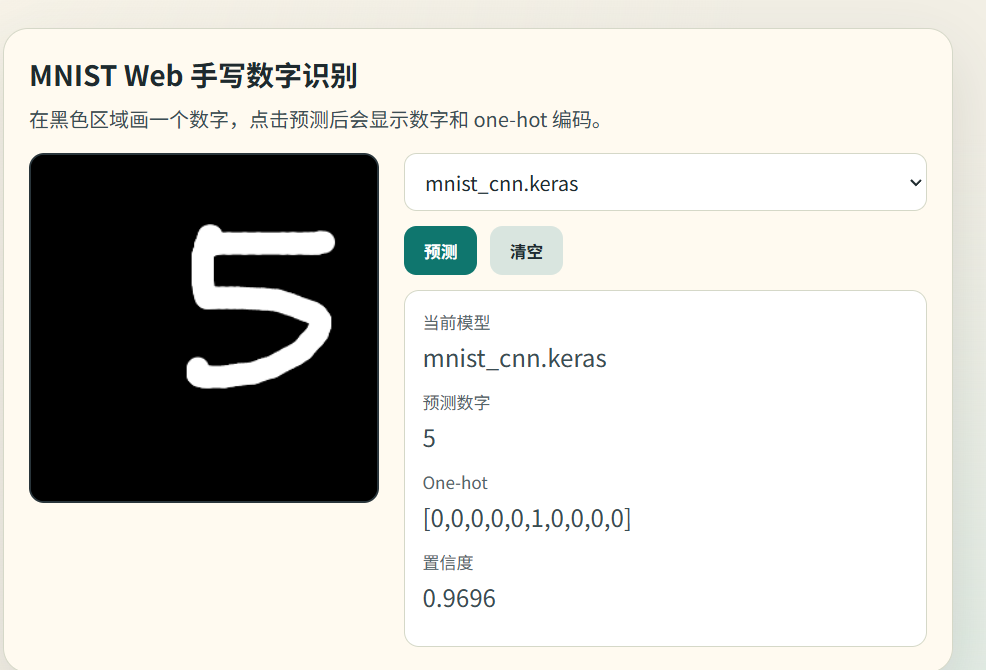
我们可以让AI挫个前端玩玩这个……
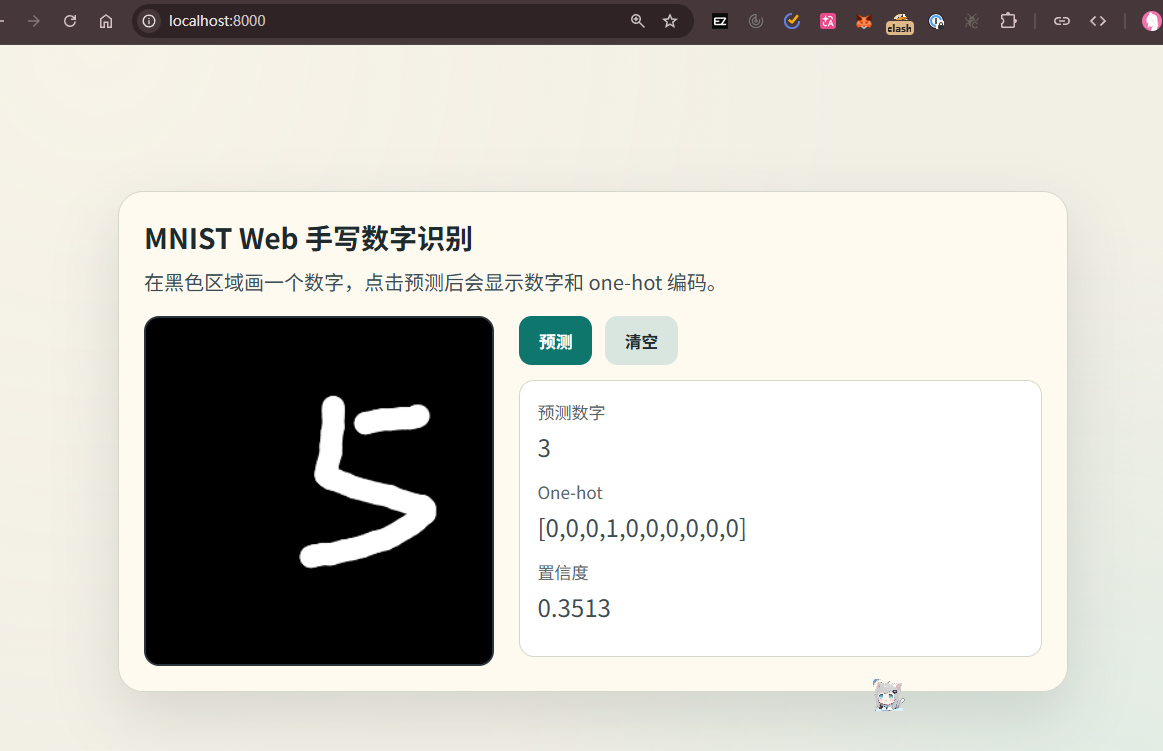
可以看到结果有时候并不准确,这是因为MLP丢失了数据集图像的结构信息,它只处理的只是数据集每张图片的所有像素,而不是它的图像结构,如果我们对数字进行平移等操作也会影响最终的结果,对于图像处理这块就要请出更适合图像的CNN了
简单的卷积神经网络 CNN
前面的数据集加载都一样,然后使用resharp对数据集进行变换,最终为28, 28, 1
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32')
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32')归一化并one-shot编码
X_train = X_train / 255
X_test = X_test / 255
y_train = utils.to_categorical(y_train)
y_test = utils.to_categorical(y_test)
num_classes = y_test.shape[1]接下来开始构建神经网络模型: 第一层隐藏层是一个卷积层来作为输入层,称为 Conv2D。该层具有 32 个特征图,大小为 5 x 5,激活函数为整流函数(Rectifier) 接下来,我们定义一个取最大值的池化层,称为 MaxPooling2D。它的池化大小配置为 2 x 2,池化用来保留卷积的特征图中的最大值,减少参数并增加特征 下一层是一个使用 dropout 的正则化层。它被配置为在该层中随机排除 20% 的神经元,以减少过拟合,这一层随机丢弃一些神经元,防止过拟合 然后是一个将二维矩阵数据转换为向量的层,称为 Flatten。它允许输出被标准的全连接层处理,它将二维特征图转换为一维向量,来连接到全连接层 接下来使用一个具有 128 个神经元且激活函数为整流函数(ReLU)的全连接层 最终,输出层有十个神经元对应十个类别,并使用 softmax 激活函数来输出每个类别的概率型预测
代码如下
import numpy as np
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras import utils
seed = 3
np.random.seed(seed)
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32')
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32')
X_train = X_train / 255
X_test = X_test / 255
y_train = utils.to_categorical(y_train)
y_test = utils.to_categorical(y_test)
num_classes = y_test.shape[1]
def baseline_model():
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(5, 5), input_shape=(28, 28, 1), activation='relu'))
model.add(MaxPooling2D())
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
model = baseline_model()
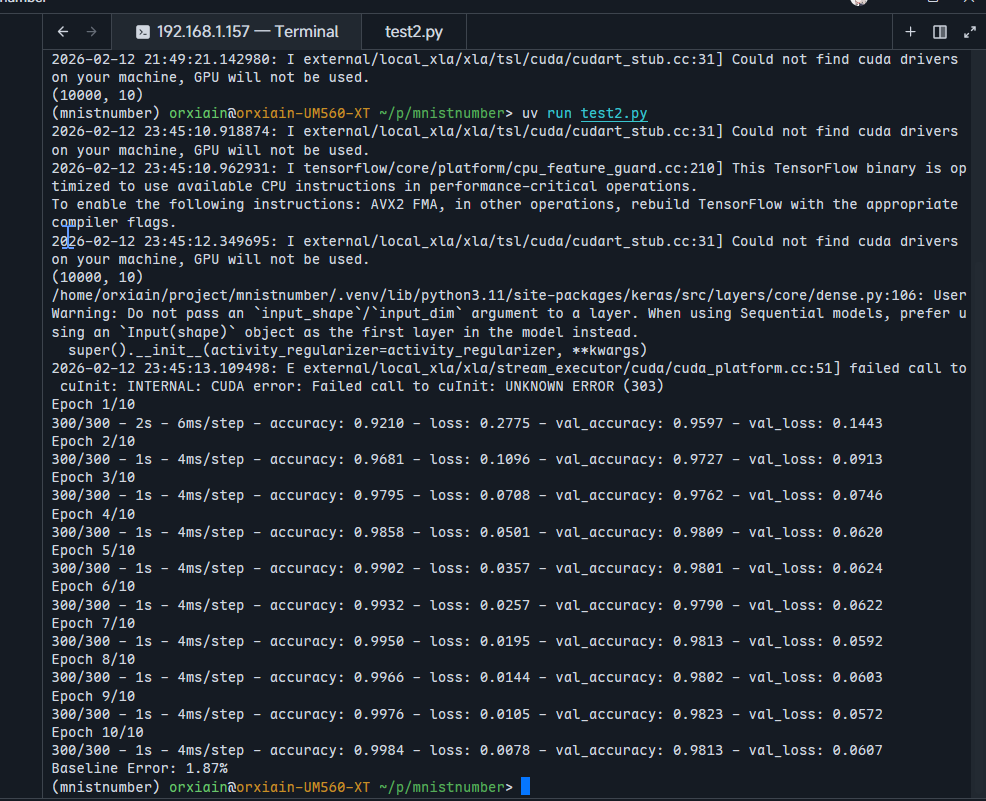
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200)
scores = model.evaluate(X_test, y_test, verbose=0)
print("%.2f%%" % (100-scores[1]*100))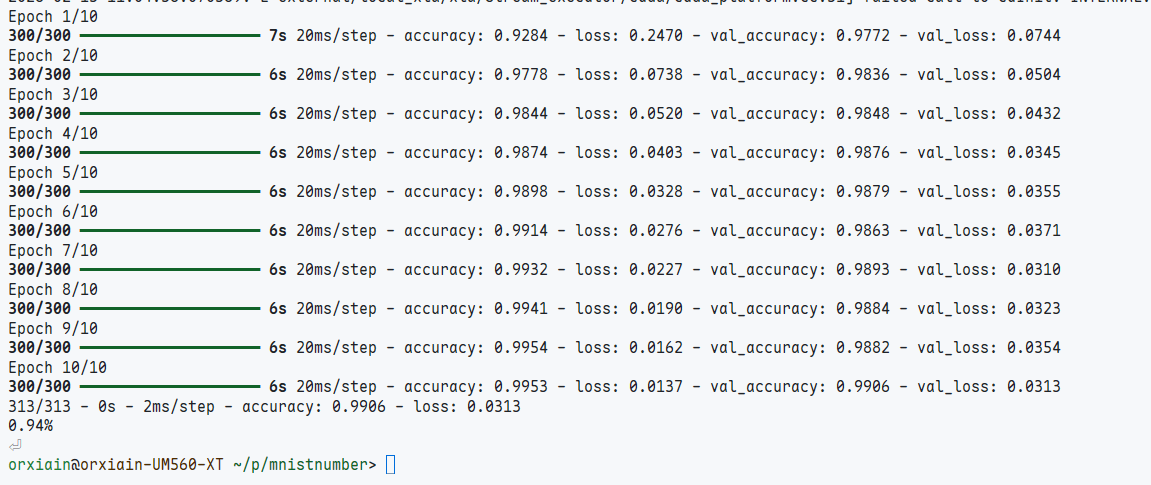 可以看到验证集的准确度和loss都是比MLP好了不少的
可以看到验证集的准确度和loss都是比MLP好了不少的
我们可以进一步使用更复杂的神经网络来提高训练效果,但是太复杂又会过拟合,下面的模型就有点复杂了,不过验证集的准确度还是提升了些
def baseline_model():
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(5, 5), input_shape=(28, 28, 1), activation='relu'))
model.add(MaxPooling2D())
model.add(Conv2D(filters=15, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D())
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model